前提条件
本教程假定RabbitMQ已安装并在标准端口(5672)上的本地主机上运行。如果您使用不同的主机,端口或凭据,连接设置将需要调整。
(使用amqp.node客户端)
在第二个教程中,我们学习了如何使用工作队列在多个Worker之间分配耗时的任务。 但是如果我们需要在远程计算机上运行一个函数并等待结果呢?那么,这是件不同的事。这种模式通常被称为远程过程调用或RPC。 在本教程中,我们将使用RabbitMQ构建一个RPC系统:一个客户端和一个可扩展的RPC服务器。由于我们没有任何值得分发的耗时任务,所以我们将创建一个返回斐波那契数列的虚拟RPC服务。
回调队列
一般来讲,通过RabbitMQ使用RPC是非常容易的。客户端发送请求消息,服务器回复响应消息。为了收到回应,请求时,我们需要发送一个callback队列地址。我们可以使用默认队列。让我们试试看:
ch.assertQueue('', {exclusive: true});
ch.sendToQueue('rpc_queue',new Buffer('10'), { replyTo: queue_name });
# ... then code to read a response message from the callback queue ...
消息属性 AMQP 0-9-1协议预定义了一组与消息一起的14个属性。除了以下属性,大多数属性很少使用:
persistent:将消息标记为persistent(值为true)或transient(false)。您可能会从第二个教程中了解到这个属性。content_type:用于描述编码的MIME类型。例如,对于经常使用的JSON编码,将此属性设置为application/json是一个很好的习惯。reply_to:通常用于命名回调队列。correlation_id:用于将RPC响应与请求相关联。
关联标识(correlation id)
在上面介绍的方法中,我们建议为每个RPC请求创建一个回调队列。这是非常低效的,但幸运的是有一个更好的方法——让我们创建一个单一的客户端回调队列。 这引发了一个新的问题,在该队列中收到回复,不清楚回复属于哪个请求。什么时候使用correlation_id属性?我们将把它设置为每个请求的唯一值。之后,当我们在回调队列中收到一条消息时,我们将查看这个属性,并基于这个属性,我们可以将响应与请求进行匹配。如果我们看到一个未知的correlation_id值,我们可以放心地丢弃这个消息——这不属于我们的请求。 您可能会问,为什么我们应该忽略回调队列中的未知消息,而不是失败并报一个错误?这是由于在服务器端的竞争条件的可能性。虽然不太可能,但在发送给我们答复之后,在发送请求的确认消息之前,RPC服务器可能会死亡。如果发生这种情况,重新启动的RPC服务器将再次处理该请求。这就是为什么在客户端,我们必须优雅地处理重复的响应,理想情况下RPC应该是幂等的。
总结
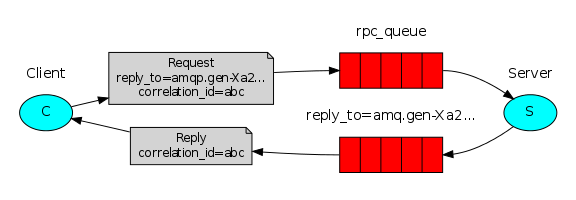
我们的RPC调用像这样: 当客户端启动的时候,它创建一个匿名的独占式回调队列。 对于一个RPC请求,客户端会发送具有这两个属性的消息:reply_to,用于设置回调队列;correlation_id,作为请求标识。 请求被发送到一个rpc_queue队列。 RPC Worker(又名:服务器)在队列上等待请求。当出现一个请求时,它执行这个工作,并使用reply_to字段中的队列将结果发送回客户端。 客户端在回调队列中等待数据。出现消息时,会检查correlation_id属性。如果它匹配来自请求的值,则返回对应用程序的响应。
全部代码
斐波那契函数:
function fibonacci(n) {
if (n == 0 || n == 1)
return n;
else
return fibonacci(n - 1) + fibonacci(n - 2);
}
我们声明斐波那契函数。它只假定有效的正整数输入(不要指望这个函数可以使用大数字,因为这可能是最慢的递归实现)。 我们的RPC服务器rpc_server.js的代码如下所示:
#!/usr/bin/env node
var amqp = require('amqplib/callback_api');
amqp.connect('amqp://localhost', function(err, conn) {
conn.createChannel(function(err, ch) {
var q = 'rpc_queue';
ch.assertQueue(q, {durable: false});
ch.prefetch(1);
console.log(' [x] Awaiting RPC requests');
ch.consume(q, function reply(msg) {
var n = parseInt(msg.content.toString());
console.log(" [.] fib(%d)", n);
var r = fibonacci(n);
ch.sendToQueue(msg.properties.replyTo,
new Buffer(r.toString()),
{correlationId: msg.properties.correlationId});
ch.ack(msg);
});
});
});
function fibonacci(n) {
if (n == 0 || n == 1)
return n;
else
return fibonacci(n - 1) + fibonacci(n - 2);
}
服务器代码非常简单:
- 像往常一样,我们首先建立连接,通道和声明队列。
- 我们可能想要运行多个服务器进程。为了在多个服务器上平均分配负载,我们需要在通道上设置
prefetch设置。 - 我们使用
Channel.consume来消费队列中的消息。然后我们进入回调函数,在那里做工作,并发回响应。
我们的RPC客户端rpc_client.js的代码:
#!/usr/bin/env node
var amqp = require('amqplib/callback_api');
var args = process.argv.slice(2);
if (args.length == 0) {
console.log("Usage: rpc_client.js num");
process.exit(1);
}
amqp.connect('amqp://localhost', function(err, conn) {
conn.createChannel(function(err, ch) {
ch.assertQueue('', {exclusive: true}, function(err, q) {
var corr = generateUuid();
var num = parseInt(args[0]);
console.log(' [x] Requesting fib(%d)', num);
ch.consume(q.queue, function(msg) {
if (msg.properties.correlationId == corr) {
console.log(' [.] Got %s', msg.content.toString());
setTimeout(function() { conn.close(); process.exit(0) }, 500);
}
}, {noAck: true});
ch.sendToQueue('rpc_queue',
new Buffer(num.toString()),
{ correlationId: corr, replyTo: q.queue });
});
});
});
function generateUuid() {
return Math.random().toString() +
Math.random().toString() +
Math.random().toString();
}
我们的RPC服务已经准备就绪。我们可以启动服务器:
./rpc_server.js
# => [x] Awaiting RPC requests
运行客户端去请求一个斐波那契数字:
./rpc_client.js 30
# => [x] Requesting fib(30)
这里介绍的设计不是RPC服务的唯一可能的实现,但它有一些重要的优点:
- 如果RPC服务器速度太慢,可以通过运行另一个来扩展。尝试在新的控制台中运行第二个
rpc_server.js。 - 在客户端,RPC需要发送和接收一条消息。因此,RPC客户端只需要一次网络往返就可以获得一个RPC请求。
我们的代码仍然非常简单,并不试图解决更复杂(但重要)的问题,如:
- 如果没有服务器运行,客户端应该如何应对?
- 客户端是否应该对RPC有某种超时?
- 如果服务器发生故障并引发异常,是否应将其转发给客户端?
- 在处理之前防止无效的传入消息(例如检查边界,类型)。